
Inside Supermicro GB300 NVL72 — A 72-GPU Blackwell Ultra Rack in Brief

Supermicro’s GB300 NVL72 is a fully liquid-cooled, rack-scale AI system that unifies 72 NVIDIA B300 (Blackwell Ultra) GPUs and 36 NVIDIA Grace CPUs into a single NVLink™ domain—built for frontier LLM training and high-throughput reasoning/test-time scaling. Key applications: AI/Deep Learning training and inference.
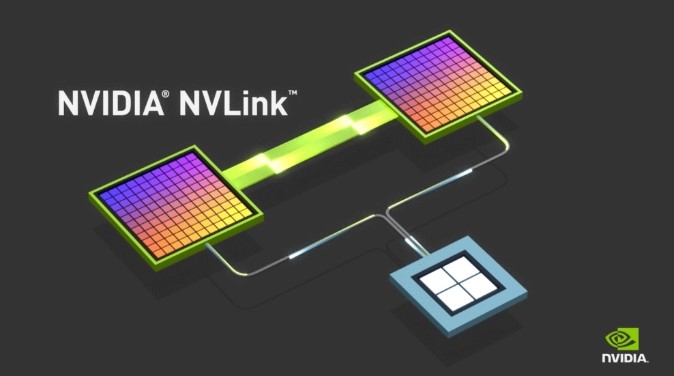
NVLink™ domain isn’t software—it’s NVIDIA’s built-in, high-speed “internal highway” that hard-wires many GPUs (and their Grace CPU partners) together using NVLink links and NVLink Switches (NVSwitch). Because the GPUs are directly connected on this highway, they can share data extremely fast and work like one big accelerator; CPUs/OS remain on their own servers—the “all-as-one” effect is about how GPUs talk to each other.
- Power shelves: 8× 1U 33 kW (each shelf with 6× 5.5 kW PSUs) — 132 kW total per rack.
- Operating power (typ.): ~132–140 kW per rack (Supermicro Blackwell solutions brochure).
- In-rack CDU: up to 250 kW cooling capacity with redundant pumps (N+1).
Rack at a glance
| Area | GB300 NVL72 (key facts) | Why it matters |
|---|---|---|
| Compute | 72× NVIDIA B300 GPUs + 36× Grace CPUs in one rack | Treats the rack like a single giant accelerator—less cross-node overhead. |
| Memory | Up to 288 GB HBM3e per GPU (≈ 21 TB HBM per rack) | Fits long contexts, massive KV caches, and MoE gating. |
| Fabric | NVLink + NVLink Switch single-domain architecture | Low-latency collectives/model parallelism without hitting the NIC. |
| Networking | NVIDIA ConnectX-8 SuperNIC, up to 800 Gb/s (IB or Ethernet) | Scales out across racks; ready for modern AI fabrics. |
| Storage | Up to 144× E1.S PCIe 5.0 NVMe (per Supermicro solution page) | High-IOPS local tiers for datasets, checkpoints, KV cache. |
| Cooling | Direct Liquid Cooling (DLC); Supermicro cites up to 40% data-center power savings | Enables >100 kW/rack density with manageable thermals/acoustics. |
| Perf (rack) | ~1.1 exaFLOPS FP4 (dense) reported by Supermicro | Throughput for large-scale inference and reasoning. |

GB300 vs. GB200 — what actually changes
- HBM per GPU: GB300 uses B300 (Blackwell Ultra) with up to 288 GB HBM3e per GPU (~21 TB rack-level), vs GB200 (B200) at ~13.4 TB per rack—unlocking longer contexts, larger KV-caches, and wider MoE. This uplift also reduces offloading to external storage and lowers recomputation overhead during long-context decoding, improving steady-state throughput on production inference.
- Inference & reasoning: GB300 NVL72 is positioned for test-time scaling/AI reasoning and leads new reasoning benchmarks at rack scale. Expect more stable latency at higher batch sizes thanks to on-rack NVLink collectives and the larger per-GPU memory footprint, which keeps KV caches and activations on-HBM.
- Compute & attention path: Blackwell Ultra delivers 2× attention-layer acceleration and ~1.5× more AI compute FLOPS vs standard Blackwell, plus native FP4 via the updated Transformer Engine—boosting real-world tokens-per-second at similar power. Mixed-precision paths (FP8/FP4) with dynamic scaling further increase utilization for decoding-heavy workloads.
- Same rack-level pattern: Both remain 72-GPU, single NVLink™ domain racks with 36 Grace CPUs, 48U form factor, 144× E1.S PCIe 5.0 bays, and DLC—so migrations focus on model/config, not topology. Existing NVL72-aware orchestration and service workflows generally carry over with minor configuration changes.
Facility quick-check (for deployments)
- Power & cooling: plan for high-density DLC; coordinate CDU choice, supply/return temps, flow rate, ΔT, and redundancy. Validate thermal budget, floor loading, and service clearances early to shorten turn-up time.
- Fabric (scale-out): design north–south links with NVIDIA ConnectX-8 SuperNIC at up to 800 Gb/s (InfiniBand or Ethernet). Keep intra-rack collectives on NVLink/NVSwitch; size inter-rack bandwidth for all-reduce, parameter-server, or RAG traffic patterns rather than GPU-to-GPU inside the rack.
Conclusion
Supermicro’s GB300 NVL72 condenses an entire AI cluster into one liquid-cooled rack—72 NVIDIA B300 (Blackwell Ultra) GPUs + 36 Grace CPUs on a single NVLink™ domain—delivering the memory headroom (up to 288 GB HBM3e per GPU) and interconnect needed for frontier LLM training and high-throughput reasoning. For facilities, direct liquid cooling can cut data-center power costs by up to 40%, while 800 Gb/s ConnectX-8 SuperNIC links make multi-rack scale-out straightforward on IB or Ethernet. In short: GB300 NVL72 pairs maximum rack-level performance with practical deployment economics—ready to drop into modern AI fabrics today.
